And the reason Spain is so well insulated is because they have limited gas interconnection so they have a 'captive supplier' in Algerian gas. Algerian gas can basically only go to Spain, Morocco or the domestic Algerian market. They have some limited LNG export capacity (which is growing and will significantly change the price Spain pays longer term).
Spain has the advantage that solar is very effective because it's further south than most of Europe. Solar now seems to be 20-25% of Spain's electricity mix (and rapidly increasing). As cost the projected costs [1]:
> We anticipate low solar capture prices of close to €25/MWh in 2027 and €20/MWh in 2028
> And the reason Spain is so well insulated is because they have limited gas interconnection so they have a 'captive supplier' in Algerian gas
Interestingly, this is also a factor in US pricing of natural gas and oil. The hotly contested (and ultimately cancelled) Keystone SL pipeline was designing to bring energy products to a wider market and ultimately to raise prices. Don't believe anyone who tells you oil companies build pipelines to lower prices. As an aside, different pipelines were built instead without the same controversy.
It's worth thinking how this would work if it didn't work like this though? Nearly all 'commodity' markets clear this way.
If you switched to 'people get paid what they bid' it's almost certain the market would just converge back to this anyway - but with a lot more gaming and guesswork (wind guessing the gas marginal price to try and get the highest price).
Unregulated free markets optimizing for the least efficient, and highest possible price to the consumer? That's interesting, because its 100% the opposite of what I've been told my whole life.
It floats oil and gas profits with huge public subsidy while ensuring nobody in the market realizes benefits from alternate sources. It slows/blocks the transition.
Why would anyone address the additional challenges and reliability concerns of renewables, when oil can be purchased for the same price? What kind of incentive does that set up?
The idea behind the regulation is that it's providing the maximum incentive to bring cheaper electricity to market.
If you try to mandate that high cost producers charge less, they will do what makes sense to control costs and then quit altogether once they are losing money.
Yes of course but the spot market and associated futures has a very big impact on any "OTC" deal that a supplier and generator does.
Like you are not going to agree a eg 3 year supply deal with $SUPPLYCO at a significantly lower price than what you could get on the spot market for it (or what you could hedge out on futures).
The issue though is that the UK spends something along the lines of £10-25bn (depending how you count subsidies) a year on renewable. Something like £10bn in direct subsidies via CfD and RO, then another ~£1.5-2bn on curtailment (paying wind farms to turn off), ~£3bn in balancing market costs, and £6bn on transmission upgrade costs (passed back to consumers/businesses) to upgrade transmission for nearly always renewable projects. There's actually a lot of others I think you could attribute to renewables but I could spend all day writing about this.
My guess is that £20bn/year is a fair cost overall in subsidy payments. This is clearly not offset by natural gas fuel savings even with elevated prices.
The UK IMO made a couple of critical mistakes. Firstly, far too much offshore wind is in Scotland when it should have been closer to population centres in England. A few factors for this but the issue is planning is devolved to Scotland (so they have every incentive to approve as many) but energy subsidies are set by Westminster. By the time UK central government realised this it was too late (or they didn't want to rock the cart for political reasons post/during Scottish independence referendum).
We're now having to pay £20-30bn+ to get Scottish wind generation down to England where it is needed (primarily through new 5 (!) 2GW HVDCs from Scotland to England). It would have been far far better just to... build those wind farms closer to England. This would have still required grid upgrades but far cheaper ones (bringing it 100-200km to population centres instead of all the way from Scotland, plus you still need to do the ones in England on top of that for the most part to get it from the HVDC landing sites to the population centres).
The second major issue is there is definitely massive diminishing returns from adding more renewables at this point. There's too many renewables on the grid a lot of the time, even if transmission was perfect - supply is outstripping demand. Instead of building more and more generation the subsidies should be redirected towards storage projects.
But overall, for the same £20bn a year you could have probably built 5 Hinckley Point C sized 3.2GW nuclear plants concurrently (assuming £4bn a year capex for 10 years). In 20 years you'd have probably 30GW of nuclear built, which should cover nearly all electricity demand in the UK in that time, with very limited transmission costs (existing nuclear plants have good grid connections and you build them close to them). And importantly, you would basically eliminate _any_ dependence on gas from the UK grid. Clearly nuclear has risks in project delivery, but at least it's reliable once built.
It's important to look at the whole picture though - most of the issues you raised are political issues, either brought about by NIMBYism or a lack of infrastructure investment over the past few decades. Without this investment (which, yes, is more expensive than it would be if it weren't also providing additional benefits tailored for renewables) the grid would continue to deteriorate. So clearly there is some amount of this cost that would need to be invested regardless.
There's also subsidies for fossil fuels to consider [0]. I don't hold these figures as gospel, but there's inarguably a massive amount of money going to propping up the (wildly profitable and hugely destructive) industry that's causing most of your raised issues in the first place - either through reduced maintenance and infrastructure investment (gotta get those shareholder returns) or lobbying/public influence campaigns.
To be clear - I absolutely agree with most of your complaints. I just see them as issues caused/exacerbated by entrenched political players, and I think the benefits to our society of getting off our fossil fuel addiction are worth the costs of modernizing our infrastructure for the long haul.
I'm certainly not saying we should stay on fossil fuels, my main point is that for the money that is being spent on various renewables could have been spent on a giant nuclear expansion at lower cost and far higher relability.
I don't really agree with this 'declining grid' narrative the renewable lobby has pushed. Yes there is upgrades to be done, etc etc. But peak UK electricity demand is down from ~65GW to ~45GW (which may change, but doesn't look to be).
Nearly all of the cost on the grid is to do with renewables, not 'general upgrades'. We would not be building 10GW of HVDC from scotland to england. We wouldn't be doing a drastic 275kV -> 400kV rerating and duplication in the middle of nowhere scotland otherwise.
Again, we're in agreement, and I yearn for a world with massive buildout of scalable nuclear power.
But what is this "renewable lobby", and how are they doing funding-wise against the various extremely well funded and deeply entrenched fossil fuel industry lobbying groups (and companies!) that have been pouring money into UK politics ever since they stopped setting UK foreign policy directly and overtly?
All I ask is that people take a step back and look at the whole picture, and then question whether their arguments benefit an industry that is responsible for so much damage and destruction (environmental, economic, human health, societal, political, etc.) or if their arguments benefit individuals and society as a whole.
Nuclear power built out in such a way as to achieve the original "too cheap to meter" goal would be a dream. But don't let perfect be the enemy of good and all that.
> But overall, for the same £20bn a year you could have probably built 5 Hinckley Point C sized 3.2GW nuclear plants concurrently (assuming £4bn a year capex for 10 years).
Planning began for Hinkley Point C in 20113. It was approved in 2016. Construction commenced in 2017-2018. It's hit major delays and is currently projected to come online in 2030. It could be delayed furhter. Unit 2 is expected about a year later [1]. Cost have ballooned to almost £50 billion [2] and may balloon further.
So you're looking at almost 20 years to build, £50 billion in costs and electricity production of ~3.2GW.
AFAICT that 3.2GW is ~7% of the UK's current electricity requirements so I'm not sure where you're getting "nearly all electricity demand". Also, 5 Hinkley Point Cs would be 16GW of electricity not 30GW.
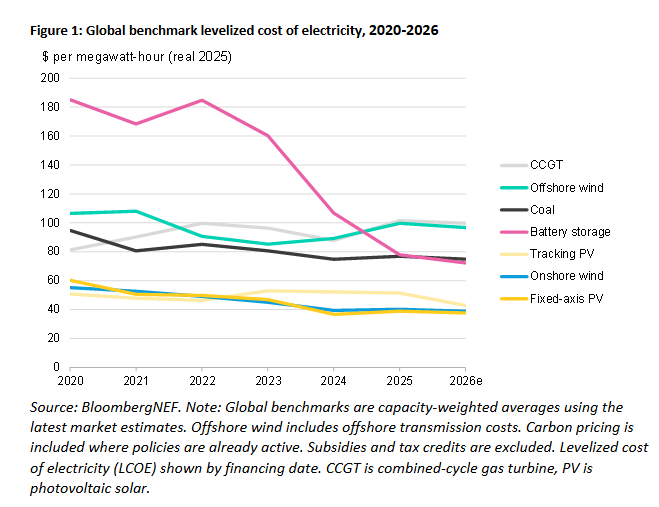
Hinkley Point C has a contracted price of £133/MWh. I imagine there's some risk-sharing and inflation in the contract so this will probably go up. Compare this to £65/MWh for new solar and £72/MWh for new onshore wind [3]. Plus of course that wind and solar projects don't take 20 years to come online.
Lastly, the only way the per MWh costs can even get that low is by giving Hinkley Point C a 60 year lifespan to amortize the cost over a sufficiently large timespan. It's likely that as the plant ages, operational costs will significantly increase beyond what's projected.
Yes of course it's hit major delays, but my point is in hindsight had we started 5 nuclear plants (sort of as planned) around HPC construction start instead of spending the money on renewables, we'd have 5 plants coming online in (say) 2030. This would be nearly 50% of the entire UK supply. Another ~10 years later you'd have another 5, giving ~30GW of baseload.
And there's no reason we couldn't have used other reactor designs, apart from lack of financing so only EDF gambled everything on the EPR for HPC (again) and failed to deliver on time/on budget (again).
>Hinkley Point C has a contracted price of £133/MWh. I imagine there's some risk-sharing and inflation in the contract so this will probably go up. Compare this to £65/MWh for new solar and £72/MWh for new onshore wind [3]. Plus of course that wind and solar projects don't take 20 years to come online.
In 2012 prices HPC was £89/MWh. AR7 is delivering (in 2012 prices) offshore wind for ~£65/MWh.
But regardless these aren't comparable at all, for the reasons I set out above. That £65/MWh often doesn't include grid upgrades (which aren't required to nearly the same scale for nuclear, as they tend to be nearish existing population/demand centres and have existing grid infra). AND you still need (expensive) backup for that wind. We are building (right now!) new gas peaking plants that are allowed by law to only operate 10 days per year. The cost per MWh if you include that capex is horrendous.
>Lastly, the only way the per MWh costs can even get that low is by giving Hinkley Point C a 60 year lifespan to amortize the cost over a sufficiently large timespan. It's likely that as the plant ages, operational costs will significantly increase beyond what's projected.
Not true, HPCs 'agreement' is for 35 years. After that they just get the market price, so it is not based on the 60 year lifespan per se.
The UK's grid upgrades are a mix of the shift to renewables but also to handle anticipated increased demand, which will be needed regardless of the electricity source or location. I don't know what the mix is however.
> Not true, HPCs 'agreement' is for 35 years. After that they just get the market price, so it is not based on the 60 year lifespan per se.
Isn't this conceding the point that costs are going to go way up as HPC ages? Why else would you have a 60 year lifespan on a plan but 35 years of agreed pricing?
UK peak power demand has _reduced_ by 15GW in the past 20ish years.
Obviously there is some investment needed but if you take a look at the capex cost of the north Scottish grid upgrades PLUS the HVDCs it's pretty terrifying.
The idea is that the financing will be "paid off" after 35 years so it doesn't require a "guaranteed" price after that (it reduces finance costs significantly when HMG is underwriting the main payback period. I expect the remaining 25 years will be extraordinarily profitable for EDF. Even if there is more maintenance costs they will have no finance costs. And finance is the main cost of HPC (60-70% goes to interest payments on the debt).
Isn't it better to build a decentralized grid out of standard parts than a few highly complex nuclear reactors? To me, that makes the system more resilient and easier to maintain. Nuclear seems like a worse choice long-term than wind/solar/batteries. Balcony solar could get us nuclear reactor levels of power per year once broadly legalized.
That's some pretty creative accounting to get to the 25bn mark. You also don't need to subsidise storage projects. They get built by market demand, as you can see by the amount being built and operated by energy trading firms who use them solely to buy power when the price is low and sell when high.
The planing issues were mostly due to the conservative party having a complete hate for onshore wind.
Nuclear fans are heavily underestimating the cost of that energy source. The levelized cost of energy per kWh today is TRIPLE that of solar already, at a negative learning curve, with a gap only widening (and accelerating so). For the very same cost per kWh, you can get double overprovisioned solar PLUS battery storage at 90% capacity factor, TODAY.
All of that fully decentralized, within the next years instead of decades, with distributed (not megacorp) ownership AND not having every other of these megaprojects cancelled due to protests.
And that figure doesn't even include externalized cost like national/environmental security or decommissioning costs.
The LCOE may be triple, but the LFSCOE [0] (full system cost, not just cost of generation) however of solar, is triple that of nuclear in Texas, and 15x that in Germany. Notice that 1. Solar Irradiance per location is actually taken into consideration and 2. Renewables have not stopped the ongoing deindustrialization of Germany due to high energy costs.
That benchmark is as outdated as completely unrealistic, as if invented by the oil/nuclear industry. Obviously 100% pure solar generation will be completely unfeasable in a place as Germany, but that completely misses the point that a realistic combo of solar/wind/biomass has a FAR higher combined capacity factor than solar alone.
Civilian Nuclear Power is a dual use technology. The UK needs to subsidize it's civilian nuclear program if it wishes to also remain a nuclear power. The alternative is it de facto becomes the 51st state of America.
The UK needs to subsidize nuclear, as well as wind, solar, and everything in between.
There's a reason countries like the US, China, Japan, India, South Korea, and others are investing in this kind of domestic capacity and spending tens to hundreds of billions to do so.
Australia and Canada have enormous uranium deposits. We're not going to have an entirely British energy supply chain (solar panels are mostly from China, etc).
And it's a relatively small amount of mass to ship - perhaps 500 tonnes of yellowcake for a reactors' yearly requirement.
Australia has the world’s largest uranium reserves. Many European countries have their own supply and could produce it if they desired to be self sufficient.
Surely gas prices would spike if the UK needed to import enough to generate an extra 125TWh. And whilst we are waiting for nuclear to come online you still need to generate energy.
How? The issue is local NIMBYs [0], anti-industry environmentalists [1], far left leaning groups [2], and even the fishing lobby [3] all attempt to obstruct wind farm expansion and make it difficult for moderates in Labour to actually execute on building energy independence for the UK.
Of course, this is also being amplified by information warfare by opponents to the UK [4][5], as can be seen by the social media campaign against offshore wind farms in the Isle of Man [6].
Frankly, the UK needs to internalize Fiona Hill's [7] position and start cracking down on fifth columnists like Farage, Corbyn, and their acolytes.
I mean offshore wind, not onshore. Thankfully most of the new ones are being built in England - check https://openinframap.org/#7.05/53.375/3.069, and these aren't curtailed.
But it was incredibly dumb to build many GW of offshore wind in Scotland when the grid was already over capacity.
I don't quite understand. The opposition can't be that insurmountable for offshore wind off England coast (instead of Scotland) given 700 giant offshore turbines are being built as we speak off the English coast. Including the world's largest windfarm (Hornsea 3).
Look at the timeline of when Hornsea 3 and these projects were initiated - most of these projects broke ground 10 to 15 years ago.
The issue is the next generation of offshore wind projects in England is up in the air. This was why Hornsea 4 [0] was cancelled by Ørsted, how the Isle of Man has mobilized against the Mooir Vannin project [1] despite it having the potential to help Liverpool and Manchester, and the Shetland's project being cancelled due to the fishing lobby [2].
What is under construction today doesn't matter because those projects started a decade ago. What matters is whether new projects are being allowed or blocked.
> But it was incredibly dumb to build many GW of offshore wind in Scotland when the grid was already over capacity.
Isn't it equally dumb to continue to bet the entire country's economy on a tiny little bit of England (and then shame the other regions as unproductive layabouts when they don't produce as much tax revenue)? Energy production is not the only, nor even the biggest imbalance in UK resources. Maybe people and businesses should go where the energy is instead of waiting for it to come to them.
Yes but if you compare urban areas (where 80% of people live in both continents) in US and Europe it's not massively different (Europe maybe 2-4 more dense depending on the country/city).
Obviously you're not going to lay fibre to the last 1% of population in the US (for the most part).
I'ts almost certainly shared. 99% of FTTH is (X)G(S)-PON which shares the fibre over a few properties. Usually something like 32 max.
The Swiss use point to point fibre (there are a few small pockets of this elsewhere). But in reality it is very hard to saturate. XGSPON has 10G/10G shared between the node. GPON has 2.4gbit down/1.2gbit up shared across the node.
In reality point to point is not really a benefit in 99.99% of scenarios, residential internet use cannot saturate 10G/10G for long, even with many 'heavy' internet users (most users can't really get more than >1gig internally over WiFi to start with).
And if it is a problem there is now 50G-PON which can run side by side, so you just add more bandwidth that way.
I had 600mbps down/200 up (I could have upgraded to 1GB) and I downgraded to 175 down/50 up (to switch to a more reliable provider) and didn’t notice any difference (family of 4).
XGSPON is actually 40Gbps down, 10Gbps up. The 40Gbps is actually four separate 10Gbps downlinks on different frequencies. Filters are used so that each customer only sees one of those downlinks. Just a little note.
> In reality point to point is not really a benefit in 99.99% of scenarios, residential internet use cannot saturate 10G/10G for long, even with many 'heavy' internet users (most users can't really get more than >1gig internally over WiFi to start with).
This is so true! The whole thing about Netflix is such a canard. A 4K stream from Netflix tops out at 16Mbps. Other streaming services use 25Mbps, or speeds in between. 40Gbps is 1600 individual 4K streams, but XGSPON can only be split to a maximum of 128 customers. I guess if all of those customers have more than 12 televisions going at once…
You’re more likely to see congestion from many customers all hitting a speed test server at once just to see how shiny the numbers are.
You're confusing XGS-PON with NG-PON2. NG-PON2 isn't really used anywhere AFIAK, the "real" upgrade path is 50G-PON (50G/50G shared). NG-PON2's tunable lasers are expensive so didn't get traction.
Sweden doesn't use much PON either. If a countries fiber build out started before gpon was released or got popular you likely continue a lot with point to point. There's a small drawback, TDM/A for the uplink, introduces some jitter but guessing it's not as bad as cable.
Well a GPON frame is 0.125ms. So the best jitter is ~0.125ms, but even if the entire upstream segment was saturated you'd be looking at probably 1-2ms at absolute worse case. The OLT will not allow one user to hammer the upstream badly like you get with DOCSIS.
So it's really a non issue (XGS-PON is even better as more data per frame means heavy upstream 'clears' the frames quicker), IME consumer routers add more jitter themselves even with ethernet on the LAN side (and WiFi is a lot worse).
Interestingly enough, most providers still run PON, but all their equipment, including splitters, is at the telco's end of the P2P connection. Apparently it is slightly cheaper to build out a PoP like that.
Yep, exactly! I live in Switzerland. The article is misleading. Switzerland doesn't have 25 Gbit consumer internet, quite obviously, as nowhere does. It has a state-owned telco that advertises 10 Gbit to ordinary consumers without making it obvious to the buyer that they won't be able to use anything above 1Gbit without exotic and expensive equipment they are near-guaranteed to not have (unless they're literally a high speed networking hobbyist).
I noticed this years ago and thought it was an extremely sharp and therefore unSwiss practice, that in a more free market with better regulation and a more feral press would have already attracted a rap on the knuckles from the truth-in-advertising people. But Swisscom is government owned and has fingers in a thousand pies, so they're allowed to get away with it.
Unfortunately because regular consumers just compare numbers and assume higher is always better, this practice has dragged fully private ISPs into offering it now too. So the entire market is just engaged in systemic consumer fraud by this point. God knows how many people are overpaying for bandwidth their machines literally can't use without realizing it.
That said, the basic point Schüller is making is sound that the fiber cables themselves are more like roads than internet. They aren't a natural monopoly but the cost of overbuild is so high that it makes sense to treat it like one. It's just a pity that in the end this doesn't make a difference as big as the article seems to be advertising in its title.
Just FYI, MoE doesn't really save (V)RAM. You still need all weights loaded in memory, it just means you consult less per forward pass. So it improves tok/s but not vram usage.
It does if you use an inference engine where you can offload some of the experts from VRAM to CPU RAM.
That means I can fit a 35 billion param MoE in let's say 12 GB VRAM GPU + 16 gigs of memory.
With that you are taking a significant performance penalty and become severely I/O bottlenecked. I've been able to stream Qwen3.5-397B-A17B from my M5 Max (12 GB/s SSD Read) using the Flash MoE technique at the brisk pace of 10 tokens per second. As tokens are generated different experts need to be consulted resulting in a lot of I/O churn. So while feasible it's only great for batch jobs not interactive usage.
> So while feasible it's only great for batch jobs not interactive usage.
I mean yeah true but depends on how big the model is. The example I gave (Qwen 3.5 35BA3B) was fitting a 35B Q4 K_M (say 20 GB in size) model in 12 GB VRAM. With a 4070Ti + high speed 32 GB DDR5 ram you can easily get 700 token/sec prompt processing and 55-60 token/sec generation which is quite fast.
On the other hand if I try to fit a 120B model in 96 GB of DDR5 + the same 12 GB VRAM I get 2-5 token/sec generation.
Your 120B model likely has way more active parameters, so it can probably only fit a few shared layers in the VRAM for your dGPU. You might be better off running that model on a unified memory platform, slower VRAM but a lot more of it.
10 tok/s is quite fine for chatting, though less so for interaction with agentic workloads. So the technique itself is still worthwhile for running a huge model locally.
You never need to have all weights in memory. You can swap them in from RAM, disk, the network, etc. MOE reduces the amount of data that will need to be swapped in for the next forward pass.
Yes you're right technically, but in reality you'd be swapping them the (vast?) majority in and out per inference request so would create an enormous bottleneck for the use case the author is using for.
You don't have to only have the experts being actively used in VRAM. You can load as many weights as will fit. If there is a "cache miss" you have to pay the price to swap in the weights, but if there is a hit you don't.
With unified memory, reading from RAM to GPU compute buffer is not that painful, and you can use partial RAM caching to minimize the impact of other kinds of swapping.
AMD Strix Halo. Available in the Framework desktop, various mini PCs, and the Asus Rog Flow Z13 "gaming tablet." The Z13 is still at $2700 for 128 GB which is an incredible deal with today's RAM prices.
Would be interesting to know for other retailers though and how much of this is down to what Walmart sells?
I'm confused by the comment that it failed because it forced single item purchases. Most of my "ecommerce" use is researching and buying one item at a time.
I think in large part the average Walmart consumer does not shop like the average Amazon consumer. They load up a big cart over time rather than pull the trigger on lots of smaller, convenience-driven purchases. So Walmart is going to view a smaller cart size as a potential failure primarily because their operations are not optimized the same way that Amazon is.
It's a failure for e-commerce vendors because it's a spectacular success for shoppers, and the relationship between sellers and buyers is almost always adversarial.
{kind=link}
https://www.gov.uk/government/publications/electricity-gener... https://www.gov.uk/government/publications/energy-profits-le...
And the reason Spain is so well insulated is because they have limited gas interconnection so they have a 'captive supplier' in Algerian gas. Algerian gas can basically only go to Spain, Morocco or the domestic Algerian market. They have some limited LNG export capacity (which is growing and will significantly change the price Spain pays longer term).
reply