These numbers were originally posted by the very active user simonw just 9 days ago [0].
Since then, they've increased to:
- "show hn" "llm" – 2,417 (+54)
- "show hn" "ai" – 13,376 (+248)
- "show hn" "vibe coded" – 23 (past month)
That’s about 6 LLM-related and 27 AI-related posts per day, just in the "show hn" category.
When I first saw this thread earlier today, there were 12 AI-related posts on the front page. Even more oddly, threads unrelated to AI somehow still end up getting hijacked by AI-related comments.
I use AI and find it very useful, but I really don’t see the reason to bring it up all the time. Not everything needs to be framed around AI, and constantly forcing it into unrelated discussions just dilutes real conversations. It feels less like enthusiasm and more like obsession.
Honestly, I wouldn’t be surprised if there is a non-negligible amount of astroturfing going on across HN.
That tracks. Intel's updated AVX10 whitepaper[1] from a few months back seems to confirm this. It explicitly states 512-bit AVX will be standard for both P and E cores, moving away from 256-bit only configs. This strongly implies AVX-512 is making a proper comeback, not just on servers but future consumer CPUs with E-cores too. Probably trying to catch up with AMD's wider AVX-512 adoption.
Nice find! I really hope so, as AVX512 is something interesting to play around with and i am pretty sure, it will play a bigger role in the future, especially with AI and all that stuff around it!
If all you need is a good starting point, why not just use a framework or library?
Popular libraries/frameworks that have been around for years and have hundreds of real engineers contributing, documenting issues, and fixing bugs are pretty much guaranteed to have code that is orders of magnitude better than something that can contain subtle bugs and that they will have to maintain themselves if something breaks.
In this very same post, the user mentions building a component library called Astrobits. Following the link they posted for the library’s website, we find that the goal is to have a "neo-brutalist" pixelated 8-bit look using Astro as the main frontend framework.
This goal would be easily accomplished by just using a library like ShadCN, which also supports Astro[1], and has you install components by vendoring their fully accessibility-optimized components into your own codebase. They could then change the styles to match the desired look.
Even better, they could simply use the existing 8-bit styled ShadCN components[2] that already follow their UI design goal.
I think AI makes personal software possible in a way that it wasn't before. Without LLMs, I would have never had the time to build a component library at all and would have probably used 8bitcn (looks awesome btw) and added the neo-brutalist shadows I wanted.
However, despite my gripes with ShadCN for Astro being minor (lots of deps + required client:load template directive), just small friction points are enough that I'm willing to quickly build my own project. AI makes it barely any work, especially when I lower the variance using parallelization.
Frameworks and libraries are useful to keep the code style the same.
Using multiple agents helps when the endgoal isn't seen. Especially if there is no end state UI design in mind. I've been using a similar method for shopify polaris[1] putting the building blocks together (and combing through docs to find the correct blocks) is still a massive chore.
I've had the opposite experience. Despite trying various prompts and models, I'm still searching for that mythical 10x productivity boost others claim.
I use it mostly for Golang and Rust, I work building cloud infrastructure automation tools.
I'll try to give some examples, they may seem overly specific but it's the first things that popped into my head when thinking about the subject.
Personally, I found that LLMs consistently struggle with dependency injection patterns. They'll generate tightly coupled services that directly instantiate dependencies rather than accepting interfaces, making testing nearly impossible.
If I ask them to generate code and also their respective unit tests, they'll often just create a bunch of mocks or start importing mock libraries to compensate for their faulty implementation, rather than fixing the underlying architectural issues.
They consistently fail to understand architecture patterns, generating code where infrastructure concerns bleed into domain logic. When corrected, they'll make surface level changes while missing the fundamental design principle of accepting interfaces rather than concrete implementations, even when explicitly instructed that it should move things like side-effects to the application edges.
Despite tailoring prompts for different models based on guides and personal experience, I often spend 10+ minutes correcting the LLM's output when I could have written the functionality myself in half the time.
No, I'm not expecting LLMs to replace my job. I'm expecting them to produce code that follows fundamental design principles without requiring extensive rewriting. There's a vast middle ground between "LLMs do nothing well" and the productivity revolution being claimed.
That being said, I'm glad it's working out so well for you, I really wish I had the same experience.
I'm starting to suspect this is the issue. Neither of these languages are in the top 5 languages so there is probably less to train on. It'd be interesting to see if this improves over time or if the gap between the languages become even more intense as it becomes favorable to use a language simply because LLMs are so much better at it.
There are a lot of interesting discussions to be had here:
- if the efficiency gains are real and llms don't improve in lesser used languages, one should expect that we might observe that companies that chose to use obscure languages and tech stacks die out as they become a lot less competitive against stacks that are more compatible with llms
- if the efficiency gains are real this might disincentivize new language adoption and creation unless the folks training models somehow address this
- languages like python with higher output acceptance rates are probably going to become even more compatible with llms at a faster rate if we extrapolate that positive reinforcement is probably more valuable than negative reinforcement for llms
Typescript/Java are pretty much the GOATs of LLM codegen, because they have strong type systems and a metric fuck ton of training code. The main problem with Java is that a lot of the training code is Java 6-8, which really poisons the well, so honestly I'd give the crown to Typescript for best LLM codegen language.
Python is good because of the sheer volume of training data, but the lack of a strong type system means you can't have a cycle of codegen -> typecheck -> codegen be automated, and you have to get the LLM to produce tests and run those, which is mostly fine but not as efficient.
Yes, I agree, that's likely a big factor. I've had a better LLM design experience using widely adopted tech like TypeScript/React.
I do wonder if the gap will keep widening though. If newer tools/tech don’t have enough training data, LLMs may struggle much more with them early on. Although it's possible that RAG and other optimization techniques will evolve fast enough to narrow the gap and prevent diminishing returns on LLM driven productivity.
I'm also suspecting this has a lot to do with the dichotomy between the "omg llms are amazing at code tasks" and "wtf are these people using these llms for it's trash" takes.
As someone who works primarily within the Laravel stack, in PHP, the LLM's are wildly effective. That's not to say there aren't warts - but my productivity has skyrocketed.
But it's become clear that when you venture into the weeds of things that aren't very mainstream you're going to get wildly more hallucinations and solutions that are puzzling.
Another observation is that I believe that when you start getting outside of your expertise you're likely going to have a correlating amount of 'waste' time spent where the LLM is spitting out solutions that an expert in the domain would immediately recognize as problematic but the non-expert will see and likely reason that it seems reasonable/or, worse, not even look at the solution and just try to use it.
100% of the time that I've tried to get Claude/Gemini/ChatGPT to "one shot" a whole feature or refactor it's been a waste of time and tokens. But when I've spent even a minimal amount of energy to focus it in on the task, curate the context and then approach? Tremendously effective most times. But this also requires me to do enough mental work that I probably have an idea of how it should work out which primes my capability to parse the proposed solutions/code and pick up the pieces. Another good flow is to just prompt the LLM (in this case, Claude Code, or something with MCP/filesystem access) with the feature/refactor/request asking it to draw up the initial plan of implementation to feed to itself. Then iterate on that as needed before starting up a new session/context with that plan and hitting it one item at a time, while keeping a running {TASK_NAME}_WORKBOOK.md (that you task the llm to keep up to date with the relevant details) and starting a new session/context for each task/item on the plan, using the workbook to get the new sessions up to speed.
Also, this is just a hunch, but I'm generally a nocturnal creature and tend to be working in the evening into early mornings. Once 8am PST rolls around I really feel like Claude (in particular) just turns into mush. Responses get slower but it seems it loses context where it otherwise wouldn't start getting off topic/having to re-read files it should already have in context. (Note; I'm pretty diligent about refreshing/working with the context and something happens in the 'work' hours to make it terrible)
I'd imagine we're going to end up with language specific llms (though I have no idea, just seems logical to me) that a 'main' model pushes tasks/tool usage to. We don't need our "coding" LLM's to also be proficient on oceanic tidal patterns and 1800's boxing history. Those are all parameters that could have been better spent on the code.
If you're willing to go the meta programming route, Rust is pretty flexible too. You can literally run python inline using macros.[1]
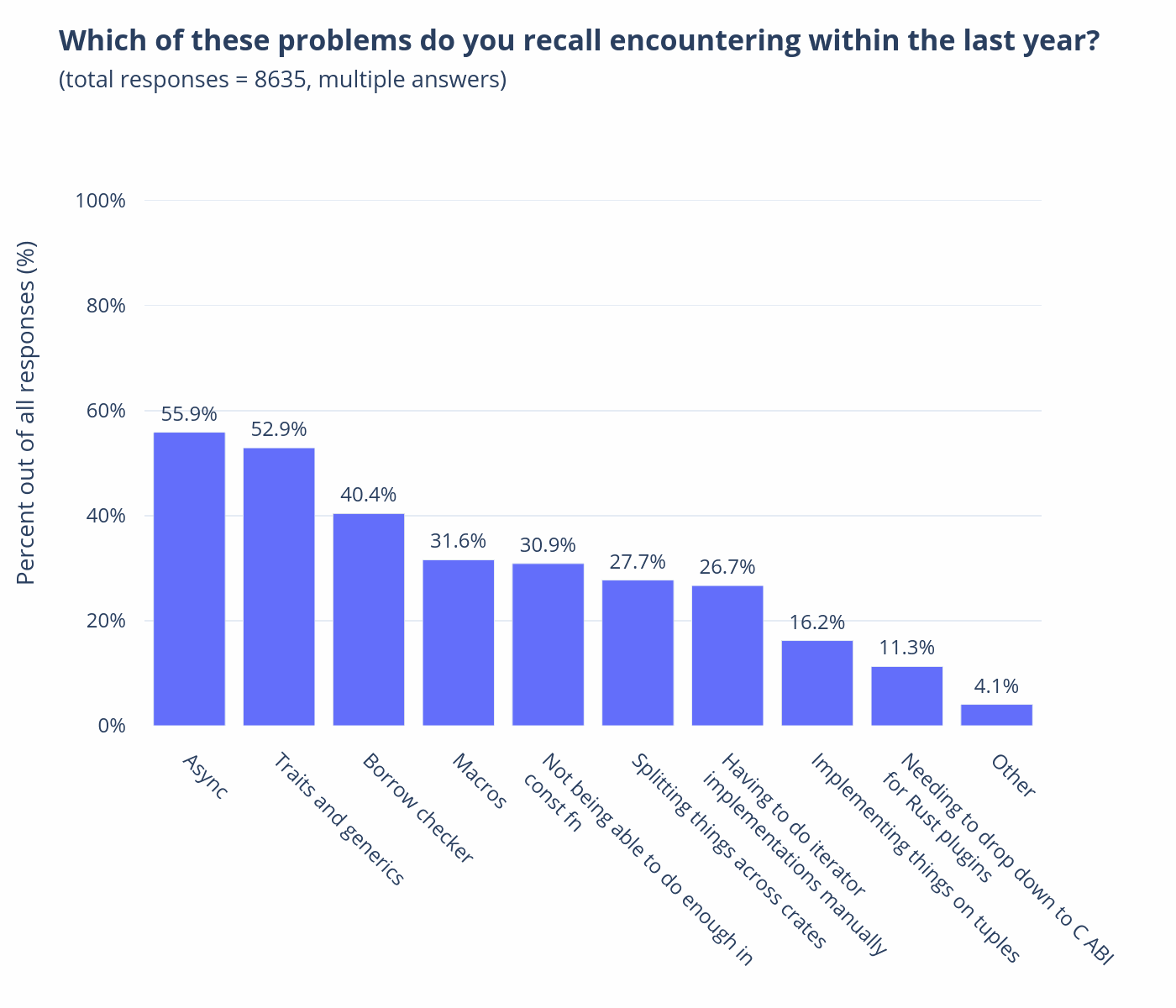
In my experience as someone that has been using Rust for a few years (and enjoys writing Rust) the biggest issue regarding adoption is that async Rust just isn't there yet when it comes to user experience.[2]
It works fine if you don't deviate from the simple stuff, but once you need to start writing your own Futures or custom locks it gets to a point that you REALLY need to understand Rust and its challenging type system.
> If you're willing to go the meta programming route, Rust is pretty flexible too. You can literally run python inline using macros.[1]
I didn’t mean like embed another languages runtime, I meant that they monkey patched Ruby to the point that they where able to run Javascript syntax as if it was plain javascript code.
It didn’t have the js runtime embedded, it was all still Ruby. The point was to showcase how much you can flex and bend the language and turn it into whatever DSL you like.
I’ve been trying to find the video but can’t find it, I believe it’s from RubyCon.
{kind=link}
According to https://hn.algolia.com/:
- "show hn" "nft" – 151 results
- "show hn" "blockchain" – 479 results
- "show hn" "crypto" – 782 results
- "show hn" "llm" – 2,363 results
- "show hn" "ai" – 13,128 results
These numbers were originally posted by the very active user simonw just 9 days ago [0].
Since then, they've increased to:
- "show hn" "llm" – 2,417 (+54)
- "show hn" "ai" – 13,376 (+248)
- "show hn" "vibe coded" – 23 (past month)
That’s about 6 LLM-related and 27 AI-related posts per day, just in the "show hn" category.
When I first saw this thread earlier today, there were 12 AI-related posts on the front page. Even more oddly, threads unrelated to AI somehow still end up getting hijacked by AI-related comments.
I use AI and find it very useful, but I really don’t see the reason to bring it up all the time. Not everything needs to be framed around AI, and constantly forcing it into unrelated discussions just dilutes real conversations. It feels less like enthusiasm and more like obsession.
Honestly, I wouldn’t be surprised if there is a non-negligible amount of astroturfing going on across HN.
[0] – [Data on AI-related Show HN posts - simonw's comment](https://news.ycombinator.com/item?id=44484996)