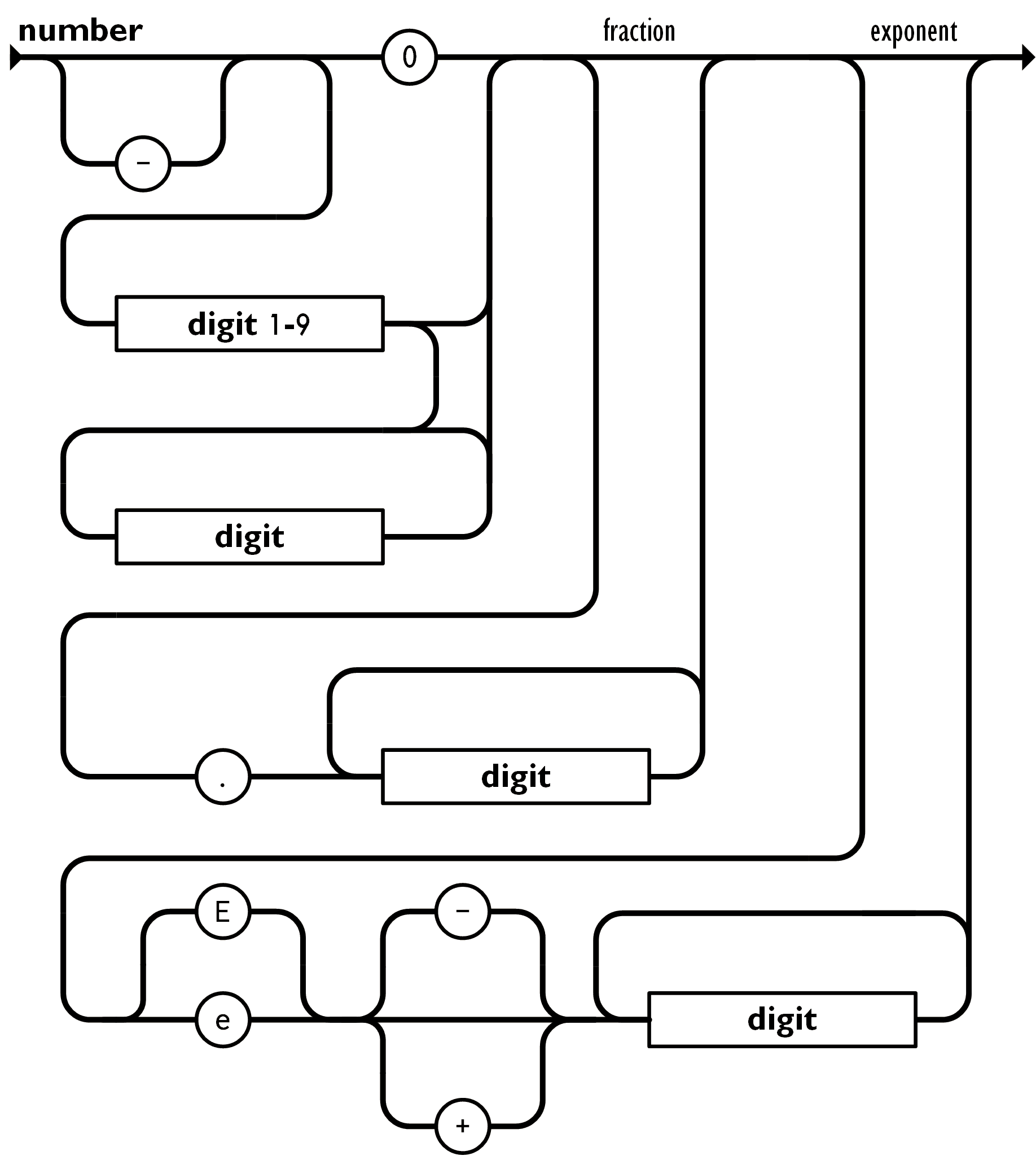
- JSON allows arbitrary integers to be represented as numeric values. That works fine on its own, but it causes serious problems if you trust the name of the format, "JavaScript Object Notation". You can't do that in JavaScript objects.
- JSON has no comments. Or version designators.
The big problems in XML are named closing tags and the weird distinction between children and attributes. JSON did those things better, by not having them at all. But XML is a long, long way from "like JSON, but worse in every way".
(Another big problem in XML-considered-as-an-ecosystem is the prevalence of people who want to deal with it by using regular expressions. As far as the technology goes, this is a non-issue -- it's a problem with the user, not the technology. But I do have to admit that the JSON equivalent appears to be loading the data into a parser that doesn't work, as opposed to loading the data into a non-parser that doesn't work.)
>JSON allows arbitrary integers to be represented as numeric values.
JSON doesn't mandate the use of binary numbers, parsers can keep number literals as strings and let the user choose whatever binary storage.
>The big problems in XML are named closing tags and the weird distinction between children and attributes. JSON did those things better, by not having them at all.
JSON has this design freedom too: should a collection of values be an object or an array?
> JSON doesn't mandate the use of binary numbers, parsers can keep number literals as strings and let the user choose whatever binary storage.
So it is a coin toss whether a perfectly valid JSON file can be processed (read/written - say pretty print) by a perfectly valid JSON library without its contents getting trashed? Quality software engineering right there.
The most obvious issue is when numbers in JSON are not parsed correctly by JSON.parse in browsers and you have to use a custom parser or keep numbers as strings, see this SO question https://stackoverflow.com/q/18755125/333777. I've encountered this several times when big numbers were serialized in Java, the Swagger said it's just a number and nothing about possible size limit and you eventually faced the issue in one of the bug reports when stuff broke.
Mostly they have to do with people believing you can parse JSON `number` elements as if they were JavaScript `Number` types. Like I said, this particular problem is not internal to the definition of JSON.
Don't confuse JSON with JavaScript. JSON is a string format. It allows arbitrary integers to be represented as numeric values. There is no such thing as implementation-defined behavior, because JSON has no behavior of any kind.
JSON is more than a string format; it's a data interchange format, and the relevant RFC (RFC8259, https://datatracker.ietf.org/doc/html/rfc8259) says that JSON allows implementations to set limits on the range and precision of numbers accepted. It also mentions explicitly that:
* good interoperability can be achieved by implementations that expect no more precision or range than IEEE754 double precision
* for such implementations, only numbers that are integers and are in the range [-(2*53)+1, (2*53)-1] are guaranteed to represent the same number on all of them.
RFC8259 also says that it allows implementations to reject strings that contain the character 'm', or to reject objects containing array values.
> An implementation may set limits on the maximum depth of nesting. An implementation may set limits on the range and precision of numbers. An implementation may set limits on the length and character contents of strings.
But those are not good ideas, and neither is rejecting numbers that are explicitly allowed by the grammar, but happen to be bigger than 9007199254740992.
There also appears to be a contradiction between these directives:
> A JSON parser MUST accept all texts that conform to the JSON grammar.
> An implementation may set limits on the size of texts that it accepts. An implementation may set limits on the maximum depth of nesting. An implementation may set limits on the range and precision of numbers. An implementation may set limits on the length and character contents of strings.
Helpfully, the RFC itself specifies which one should win:
> The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in BCP 14 [RFC2119] [RFC8174] when, and only when, they appear in all capitals, as shown here.
The discussion of limiting number values glosses over a pretty big logical hole:
> This specification allows implementations to set limits on the range and precision of numbers accepted. Since software that implements IEEE 754 binary64 (double precision) numbers [IEEE754] is generally available and widely used, good interoperability can be achieved by implementations that expect no more precision or range than these provide, in the sense that implementations will approximate JSON numbers within the expected precision. A JSON number such as 1E400 or 3.141592653589793238462643383279 may indicate potential interoperability problems, since it suggests that the software that created it expects receiving software to have greater capabilities for numeric magnitude and precision than is widely available.
Of course, integer values of more than 54 bits are also generally available and widely used. A JSON number such as 36028797018963968 does not suggest that it expects receiving software to have any greater capability for numeric magnitude or precision than is widely available. The actual reason for the mention of integer value restrictions is not discussed, but it is mentioned earlier in the RFC:
> JSON's design goals were for it to be minimal, portable, textual, and a subset of JavaScript.
These goals were not achieved, but they are still corrupting the discussion of numeric values. This RFC is a dog's breakfast. Writing "arbitrary noncompliance will be allowed" makes a mockery of the idea of a standard, and according to its own terms, the document does not even allow the restrictions it claims to allow. This document doesn't do anything except attempt to legitimate any and all existing or future "JSON parsers". There is no JSON data which, according to the lowercased restriction allowances, can be guaranteed to be accepted by a "compliant" JSON parser.
It doesn't reject those numbers, but it doesn't preserve the value across encoding/decoding. And this is not limited to JSON parsers for Javascript, it's quite hard to find a C library that doesn't have the 2^53 limitation.
Regarding limitations on text size, you can always return an out of memory error. As long as it's not a _parsing_ error, it's technically fine, you are still accepting all texts that conform to the JSON grammar but telling the client that there's not enough memory to store the parsed output.
Which has proven to have zero real-world use case.
> - JSON allows arbitrary integers to be represented as numeric values. That works fine on its own, but it causes serious problems if you trust the name of the format, "JavaScript Object Notation". You can't do that in JavaScript objects.
That's not a problem with JSON, that's a problem with standardized JavaScript. I believe JSON was named before there was an official standard that required JavaScript implementations to be terrible.
A lack of comments is never good, especially when you want to provide a workable example of what an entity looks like, while annotating its contents, but at the same time allowing it to be parseable. Furthermore, i wouldn't scoff if i ever saw comments about non-trivial fields in web APIs actually being returned, to better explain how to use them. Of course, at the same time i believe that something like that would be better suited as a part of WSDL, WADL or XSD schemas, but JSON and the technologies around it have essentially done away with strict schemas, which makes using them about as reassuring as dynamic languages - i.e. unreliable.
Far too few people do properly versioned APIs and far too few people do OpenAPI specs that are generated from code automatically and are publicly available for the above to be a moot point. Whereas with XML based services, i could open the WSDL/XSD file for a 15 year old API and know what's going on within 10 minutes. It seems like the industry has lost that bit of wisdom somewhere along the way of chasing agility - the same way that knowing how to generate code and operate with metamodels and models has also been tossed aside.
You can't expect a number from an API and get a boolean back, without your system breaking. There should be contracts between any two parts of a system, or any interlinked systems.
It's inexcusable to have breaking changes without doing something to give the users the ability to react to them before breakage: be it changing the signatures and deprecating the old methods for libraries which would be picked up by CI and would not build the code before these being addressed, or changing a WSDL/WADL/OpenAPI service description, which would then propagate into failing integration tests before new versions would be deployed.
You'd get a JSON schema of v14 and then another of v15 which would introduce breaking changes, but all of the downstream systems would see the changes and essentially figure out that they cannot use this new API (ideally, in a scheduled and automated process).
So essentially, it would be like this:
- you have an old API version that is used
- for example: your-app.com/api/v14/pictures/cats/bambino?size_x=640&size_y=480&page=5
- the new API version would get released, which would change paging semantics
- your-app.com/api/v15/pictures/cats/bambino?size_x=640&size_y=480&count=10&offset=40
- the CI system would pick up changes from /api/v14.json and /api/v15.json service descriptions
- it would detect breaking changes and developers would be alerted (either automatically as a part of integration tests, or when trying to update integrations)
- they'd update the API integration to address these issues, before the old would eventually be sunsetted
Of course, sadly most companies out there aren't interested in versioning their APIs or even providing any sorts of service descriptions, because all of that costs money and time. So in the moniker of "Move fast and break things" the focus ends up being on the second part.
> I believe JSON was named before there was an official standard that required JavaScript implementations to be terrible.
Nope. The ECMAScript standard released in 1999 already specifies:
> In ECMAScript, the set of values represents the double-precision 64-bit format IEEE 754 values including the special “Not-a-Number” (NaN) values, positive infinity, and negative infinity.
{kind=link}
- JSON allows arbitrary integers to be represented as numeric values. That works fine on its own, but it causes serious problems if you trust the name of the format, "JavaScript Object Notation". You can't do that in JavaScript objects.
- JSON has no comments. Or version designators.
The big problems in XML are named closing tags and the weird distinction between children and attributes. JSON did those things better, by not having them at all. But XML is a long, long way from "like JSON, but worse in every way".
(Another big problem in XML-considered-as-an-ecosystem is the prevalence of people who want to deal with it by using regular expressions. As far as the technology goes, this is a non-issue -- it's a problem with the user, not the technology. But I do have to admit that the JSON equivalent appears to be loading the data into a parser that doesn't work, as opposed to loading the data into a non-parser that doesn't work.)